




Navigation▲
|
Tutoriel précédent : Early-z |
Tutoriel suivant : micro-architecture |
I. Introduction▲
Au fur et à mesure que les procédés de fabrication devenaient de plus en plus étoffés, les cartes graphiques pouvaient incorporer un plus grand nombre de circuits. Les unités de traitement de la géométrie étaient autrefois câblées : elles ne pouvaient effectuer qu'un éclairage de type Phong, rien de plus. Alors certes, il était possible de configurer certains paramètres pour obtenir un éclairage proche de celui voulu, mais le type d'éclairage restait le même.
Par la suite, les unités de traitement de la géométrie sont devenues des unités programmables. Par programmable, on veut dire qu'il est possible de spécifier leur comportement via un programme informatique. Cela permet une grande flexibilité : changer le comportement ne nécessite pas de recâbler tout le circuit (ce qui est souvent impossible) : il suffit de changer la suite d'instructions à exécuter. Nos unités de traitement de la géométrie deviennent donc des processeurs indépendants, capables d'effectuer un certain nombre d'instructions sur les données de nos sommets.
Ces processeurs sont donc capables d'exécuter des programmes sur des sommets. Ces programmes sont appelés des vertex shaders. Ils sont souvent écrits dans un langage de haut niveau, le HLSL ou le GLSL, et sont traduits (compilés) par les pilotes de la carte graphique, pour les rendre compatibles avec le processeur de vertex shaders. Au début, ces langages, ainsi que le matériel, supportaient uniquement des programmes simples. Au fil du temps, les spécifications de ces langages sont devenues de plus en plus riches et le matériel en a fait autant.
L'étape de traitement des pixels est elle aussi devenue programmable. Des programmes capables de traiter des pixels, les pixels shaders, ont fait leur apparition. Une deuxième série d'unités a alors été ajoutée dans nos cartes graphiques : les processeurs de pixels shaders. Les processeurs de pixels shaders fonctionnent sur le même principe que les processeurs de vertex shaders.
Les premières cartes graphiques avaient des jeux d'instructions séparés pour les unités de vertex et les unités de pixel shaders. Et les processeurs de vertex shaders et de pixels shaders étaient séparés. Pour donner un exemple, c'était le cas de la Geforce 6800. Depuis DirectX 10, ce n'est plus le cas. Depuis, le jeu d'instructions a été unifié entre les vertex shaders et les pixels shaders.
Les premiers processeurs de shaders disposaient de peu d'instructions. On trouvait uniquement des instructions de calculs arithmétiques, dont certaines étaient assez complexes (logarithmes, racines carrées, etc.). Depuis, d'autres versions de vertex shaders ont vu le jour. Pour résumer, les améliorations ont porté sur :
- le nombre de registres ;
- la taille de la mémoire qui stocke les shaders ;
- le support des branchements ;
- l'ajout d'instructions d'appel de fonctions ;
- le support de fonctions imbriquées ;
- l'ajout d'instructions de lecture/écriture en mémoire centrale ;
- l'ajout d'instructions capables de traiter des nombres entiers ;
- l'ajout d'instructions bit à bit.
Un processeur de shaders contient évidemment des registres. Il dispose notamment de registres généraux, qui servent à stocker des résultats temporaires de calcul. À côté, on trouve des registres qui servent à stocker des constantes. Ils permettent de stocker les matrices servant aux différentes étapes de transformation, de stocker les positions des sources de lumière pour l'éclairage, etc. Ces constantes sont placées dans ces registres lors du chargement du vertex shader dans la mémoire vidéo : les constantes sont chargées un peu après. Toutefois, le vertex shader peut écrire dans ces registres, au prix d'une perte de performance particulièrement violente.
Le choix de la constante à utiliser dans une instruction s'effectue en utilisant un registre : le registre d'adresse de constante. Celui-ci va permettre de préciser quel est le registre de constante à sélectionner dans une instruction. Une instruction peut ainsi lire une constante depuis les registres constants et l'utiliser dans ses calculs.
II. Processeurs SIMD▲
Sur tous les processeurs de traitement de sommets, il est possible de traiter plusieurs morceaux de sommets à la fois. Pour cela, les processeurs de traitement de sommets utilisent des instructions spécialisées, qui peuvent manipuler un grand nombre de données simultanées. Il existe deux techniques :
- les instructions vectorielles ;
- les instructions VLIW.
Les instructions sont vectorielles : elles travaillent sur un ensemble de données de même taille et de même type. Ces données sont rassemblées dans des espèces de blocs de données, d'une taille fixe, qu'on appelle vecteurs. Ces vecteurs contiennent plusieurs nombres entiers ou nombres flottants placés les uns à côté des autres.
Une instruction de calcul vectoriel va traiter chacune des données du vecteur indépendamment des autres. Par exemple, une instruction d'addition vectorielle va additionner ensemble les données qui sont à la même place dans deux vecteurs et mettre le résultat dans un autre vecteur, toujours à la même place. Quand on exécute une instruction sur un vecteur, les données présentes dans ce vecteur sont traitées simultanément.

Elles sont utilisées dans la quasi-totalité des cartes graphiques Nvidia et dans les cartes AMD/ATI récentes. Seules les vieilles cartes graphiques AMD utilisaient du VLIW.
II-A. Geforce 3▲
La première carte graphique commerciale destinée aux joueurs et disposant d'une unité de vertex programmable est la Geforce 3. Celle-ci respectait le format de vertex shader 1.1. L'ensemble des informations à savoir sur cette unité est disponible dans l'article « An user programmable vertex engine », disponible sur le net.
Le processeur de cette carte était capable de gérer un seul type de données : les nombres flottants de norme IEEE754. Toutes les informations concernant la coordonnée d'un sommet, voire ses différentes couleurs, devaient être encodées en utilisant ces flottants. De nos jours, les processeurs de sommets sont capables de gérer des nombres entiers et les instructions qui vont avec.
Ce processeur est capable d'exécuter 17 instructions différentes.
Voici la liste de ces instructions :
|
OpCode |
Nom |
Description |
|
MOV |
Move |
vector -> vector |
|
MUL |
Multiply |
vector -> vector |
|
ADD |
Add |
vector -> vector |
|
MAD |
Multiply and add |
vector -> vector |
|
DST |
Distance |
vector -> vector |
|
MIN |
Minimum |
vector -> vector |
|
MAX |
Maximum |
vector -> vector |
|
SLT |
Set on less than |
vector -> vector |
|
SGE |
Set on greater or equal |
vector -> vector |
|
RCP |
Reciprocal |
scalar-> replicated scalar |
|
RSQ |
Reciprocal square root |
scalar-> replicated scalar |
|
DP3 |
3 term dot product |
vector-> replicated scalar |
|
DP4 |
4 term dot product |
vector-> replicated scalar |
|
LOG |
Log base 2 |
miscellaneous |
|
EXP |
Exp base 2 |
miscellaneous |
|
LIT |
Phong lighting |
miscellaneous |
|
ARL |
Address register load |
miscellaneous |
Comme on le voit, ces instructions sont presque toutes des instructions arithmétiques. On y trouve des multiplications, des additions, des exponentielles, des logarithmes, des racines carrées, etc. À côté, on trouve des comparaisons (SDE, SLT), une instruction MOV qui déplace le contenu d'un registre dans un autre et une instruction de calcul d'adresse. Fait intéressant, toutes ces instructions peuvent s'exécuter en un seul cycle d'horloge.
On remarque que parmi toutes ces instructions arithmétiques, la division est absente. Il faut dire que la contrainte qui veut que toutes ces instructions s'exécutent en un cycle d'horloge pose quelques problèmes avec la division, qui est une opération plutôt lourde en hardware. À la place, on trouve l'instruction RCP, capable de calculer 1/x, avec x un flottant. Cela permet ainsi de simuler une division : pour obtenir Y/X, il suffit de calculer 1/X avec RCPet de multiplier le résultat par Y.
Autre manque : les instructions de branchement. C'est un fait, ce processeur ne peut pas effectuer de branchements. À la place, il doit simuler ceux-ci en utilisant des instructions arithmétiques. C'est très complexe, et cela limite un peu les possibilités de programmation. À l'époque, ces branchements n'étaient pas utiles, sans compter que les environnements de programmation ne permettaient pas d'utiliser de branchements lors de l'écriture de shaders. De nos jours, les cartes graphiques récentes peuvent effectuer des branchements ou, du moins, des instructions similaires.
On remarque qu'il n'y a aucune instruction d'accès à la mémoire. Notre processeur ne peut pas aller chercher d'informations dans la mémoire vidéo. Le processeur de la Geforce 3 doit se contenter de ses registres. Depuis, la situation a changé : les cartes graphiques récentes peuvent aller lire certaines données depuis la mémoire vidéo.
II-B. Instructions à prédicats▲
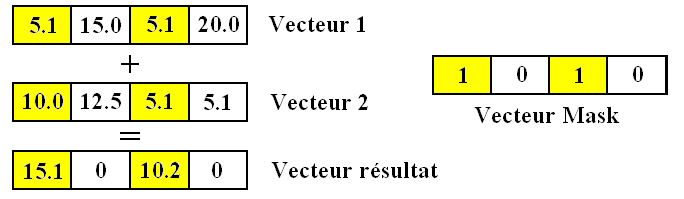
Ces instructions vectorielles sont très utiles quand on doit effectuer un traitement identique sur un ensemble de données similaires. Mais dès que le traitement à effectuer sur nos données varie suivant le résultat d'un test ou d'un branchement, les choses se gâtent. Mine de rien, avec une instruction vectorielle, on est obligé de calculer et de modifier tous les éléments d'un paquet : il est impossible de zapper certains éléments d'un paquet dans certaines conditions. Par exemple, imaginons que je veuille additionner ensemble les éléments d'un paquet seulement s'ils sont positifs : je ne peux pas le faire avec une instruction vectorielle « normale ». Du moins, pas sans aide.
Pour résoudre ce problème, certains processeurs de traitement de sommets utilisent des instructions à prédicats. Pour faire simple, ces instructions sont des instructions « annulables ». Elles ne modifient un élément d'un vecteur que si celui-ci remplit une condition. Pour cela, notre processeur de traitement de sommets contient un registre masque de sommet (vector mask register). Celui-ci stocke des informations qui permettront de sélectionner certaines données et pas d'autres pour faire notre calcul. Il est mis à jour par des instructions de comparaison.
Ce registre masque de sommet va stocker des bits pour chaque flottant présent dans le vecteur à traiter. Si ce bit est à 1, notre instruction doit s'exécuter sur la donnée associée à ce bit. Sinon, notre instruction ne doit pas la modifier. On peut ainsi traiter seulement une partie des registres stockant des vecteurs SIMD.
III. Processeurs VLIW▲
Autre solution : faire de nos streams processors des processeurs VLIW. Sur ces processeurs VLIW, nos instructions sont regroupées dans ce qu'on appelle des paquets, des sortes de super-instructions. Ces paquets sont découpés en morceaux de taille bien précise, dans lesquels il va venir placer les instructions élémentaires à faire exécuter.
|
Instruction VLIW à 3 tranches |
||
|
Tranche 1 |
Tranche 2 |
Tranche 3 |
|
Addition |
Multiplication |
Décalage à gauche |
Chaque tranche sera attribuée à une unité de calcul bien précise. Par exemple, la première tranche sera attribuée à la première ALU, la deuxième à une autre ALU, la troisième à la FPU, etc. Ainsi, l'unité de calcul exécutant l'instruction sera précisée via la place de l'instruction élémentaire, la tranche dans laquelle elle se trouve.
Qui plus est, vu que chaque tranche sera attribuée à une unité de calcul différente, le compilateur peut se débrouiller pour que chaque instruction dans un paquet soit indépendante de toutes les autres instructions dans ce paquet. Lorsqu'on exécute un paquet, il sera décomposé par le séquenceur en petites instructions élémentaires qui seront chacune attribuées à l'unité de calcul précisée par la tranche qu'elles occupent. Pour simplifier la tâche du décodage, on fait en sorte que chaque tranche ait une taille fixe.
Dans la majorité des cas, ces unités VLIW sont capables de traiter deux instructions arithmétiques en parallèle : une qui sera appliquée aux couleurs R, G et B, et une autre qui sera appliquée à la couleur de transparence. Cette possibilité s'appelle la co-issue.
IV. Streams processeurs▲
De nos jours, les processeurs de sommets ou de pixels sont tous identiques, et peuvent servir à faire aussi bien des calculs graphiques que des calculs sur des données quelconques. Ces processeurs sont ce qu'on appelle des streams processors, des processeurs spécialement conçus pour exécuter des suites d'instructions sur un grand nombre de données.
Sur ces processeurs, des programmes, nommés kernels, sont appliqués entièrement à un tableau de données que l'on appelle un stream. Dans nos cartes graphiques actuelles, ce stream est découpé en morceaux qui seront chacun traités sur un stream processor. Chacun de ces morceaux est appelé un thread. Vous remarquerez que le terme thread est ici utilisé dans un sens différent de celui utilisé précédemment. Faites attention ! Quoi qu'il en soit, ces processeurs ressemblent fortement aux processeurs vectoriels ou aux processeurs utilisant des instructions SIMD.
Un GPU actuel est souvent composé de plusieurs de ces streams processors, placés ensemble sur une même puce, avec quelques autres circuits annexes, utilisés dans les tâches de rendu 3D. Ces streams processors sont alors pilotés par un gros microcontrôleur qui se charge de découper le stream à traiter en threads, avant de les répartir sur les différents streams processors de la puce.
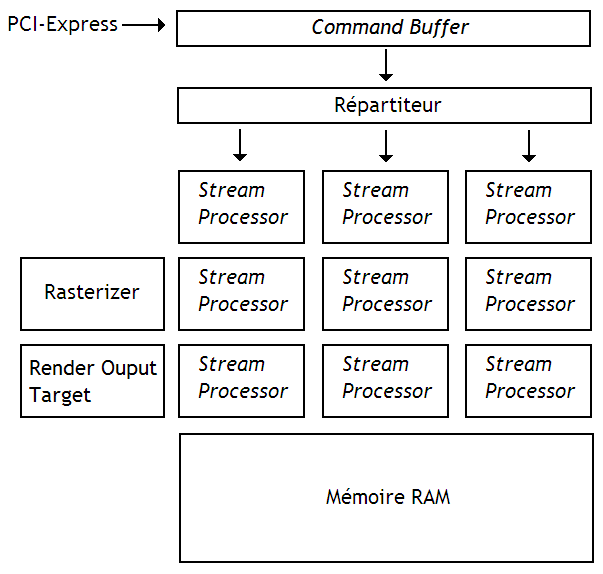
Le découpage du stream en threads se fait à l'exécution. En clair : on envoie à notre carte 3D des informations sur le tableau à manipuler et celle-ci se débrouille toute seule pour le découper en morceaux et les répartir sur les processeurs disponibles.
IV-A. Streams processors▲
Ces streams processors sont comme les processeurs de sommets ou de pixels normaux. Plus précisément, il s'agit de processeurs SIMD, comme on l'a vu dans le chapitre précédent. Ils traitent donc des vecteurs de taille fixe. La différence avec un simple processeur SIMD vient toutefois de leur communication avec la mémoire, et de l'organisation des registres.
À première vue, les schémas ci-dessus ne ressemblent à rien de connu. Et pourtant, on peut déjà faire quelques remarques assez intéressantes.
IV-B. Register files▲
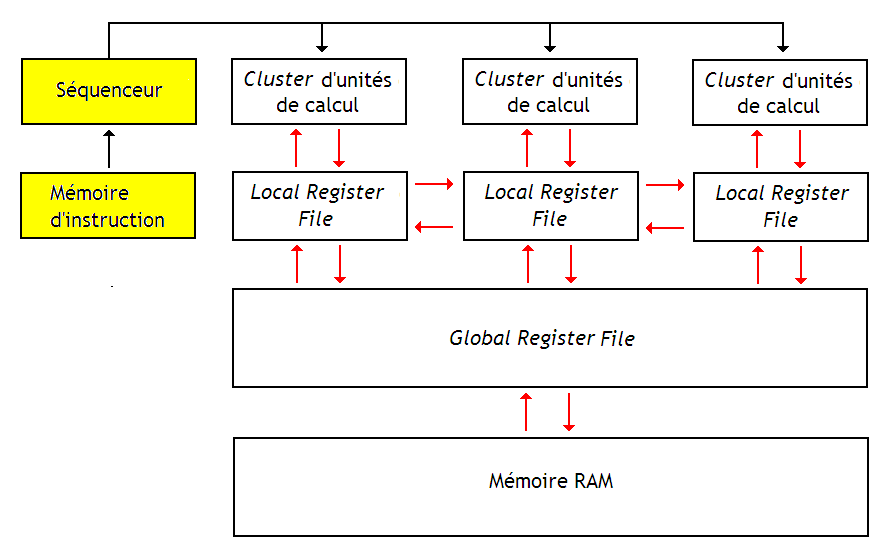
Sur un processeur, les registres sont tous regroupés dans de grosses mémoires RAM qu'on appelle des fichiers de registres (register files). On en trouve dans des tas de processeurs et pas seulement dans des streams processors. Dans nos streams processors, on remarque que l'on en a plusieurs. On trouve d'abord quelques fichiers de registres locaux. Ceux-ci sont directement connectés aux unités de calcul. C'est dans ces fichiers de registres locaux que nos unités de calcul vont aller chercher les données qu'elles doivent manipuler. Plus bas, ces fichiers de registres locaux sont reliés à un fichier de registres plus gros, le fichier de registres global, lui-même relié à la mémoire.
C'est très différent de ce qu'on trouve sur les processeurs plus habituels. D'habitude, on ne dispose pas de plusieurs couches de registres. Alors pourquoi en trouve-on plusieurs ici ? Le fait est que nos streams processors et nos GPU disposent d'une grande quantité d'unités de calcul. Et cela peut facilement monter à plus d'une centaine ou d'un millier d'ALU ! Si on devait relier toutes ces unités de calcul à un gros fichier de registres, cela poserait pas mal de problèmes. Si on faisait ça, on se retrouverait avec un fichier de registres énorme, lent, et qui chaufferait beaucoup trop.
Pour garder un fichier de registres rapide et pratique, on est obligé de limiter le nombre d'unités de calcul connectées dessus, ainsi que le nombre de registres contenus dans le fichier de registres. La solution est donc de casser notre gros fichier de registres en plusieurs plus petits, reliés à un fichier de registres plus gros, capable de communiquer avec la mémoire. Ainsi, nos unités de calcul vont aller lire ou écrire dans un fichier de registres local très rapide.
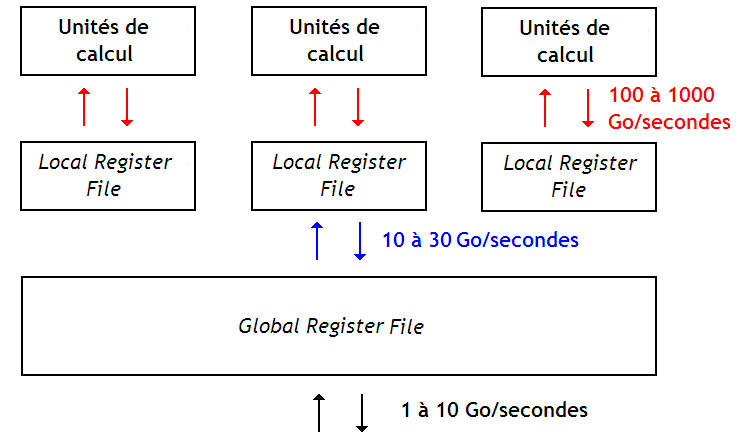
Notre fichier de registres global va en quelque sorte servir d'intermédiaire entre la mémoire RAM et le fichier de registres local. Un peu comme une mémoire cache. La différence entre ce fichier global de registres et un cache vient du fait que les caches sont souvent gérés par le matériel, tandis que ces fichiers de registres sont gérés via des instructions-machine. Le processeur dispose ainsi d'instructions pour transférer des données entre les fichiers de registres ou ceux-ci et la mémoire. Leur gestion peut donc être déléguée au logiciel, qui saura les utiliser au mieux.
Notre fichier de registres global va servir à stocker un ou plusieurs threads destinés à être traités par notre stream processor. Il peut aussi servir à transférer des données entre les fichiers de registres locaux ou à stocker des données globales, utilisées par des Clusters d'ALU différents. Quant à nos fichiers de registres locaux, ils vont servir à stocker des morceaux de threads en cours de traitement : tous les résultats temporaires vont aller dans ce fichier de registres local, afin d'être lus ou écrits le plus rapidement possible.
Navigation▲
|
Tutoriel précédent : Early-z |
Tutoriel suivant : micro-architecture |
