




I. Introduction▲
Un ordinateur n'est jamais un composant parfait, ce qui fait que des pannes peuvent survenir de temps à autre. Ces pannes peuvent être aussi bien logicielles (un logiciel qui plante ou qui a un bogue), que matérielles (un composant qui cesse de fonctionner ou qui donne un résultat faux). Certaines erreurs peuvent être transitoires et ne se manifester qu'occasionnellement, tandis que d'autres sont de vraies pannes qui empêchent le bon fonctionnement d'un ordinateur tant qu'elles ne sont pas résolues.
Pour donner un exemple de panne transitoire, on peut citer l'incident de Schaerbeek. Le 18 mai 2003, dans la petite ville belge de Schaerbeek, on constata une erreur sur la machine à voter électronique de la commune : il y avait un écart de 4096 voix en faveur d'un candidat entre le dépouillement traditionnel et le dépouillement électronique. Mais ce n'était pas une fraude : le coupable était un rayon cosmique, qui avait modifié l'état d'un bit de la mémoire de la machine à voter. Et si les pannes causées par des rayons cosmiques sont rares, d'autres pannes peuvent avoir des conséquences similaires.
Dans des milieux comme l'aéronautique, les satellites, ou dans tout système dit critique, on ne peut pas se permettre que de telles pannes aient des conséquences : des vies peuvent être en jeu. Dans une telle situation, on doit limiter l'impact des pannes. Pour cela, il existe des systèmes tolérants aux pannes, qui peuvent continuer de fonctionner, même en ayant un ou plusieurs composants en panne.
Cette tolérance aux pannes se base sur la redondance : on duplique du matériel, des données, ou des logiciels en plusieurs exemplaires. Ainsi, si un exemplaire tombe en panne, les autres pourront prendre la relève. Dans nos ordinateurs, cette redondance peut prendre plusieurs formes :
- une redondance des données, qui est à la base des codes correcteurs d'erreurs et des systèmes RAID ;
- une redondance matérielle : on duplique des serveurs, des unités de calcul, des processeurs ou de la mémoire, des disques durs (RAID), et ainsi de suite ;
- une redondance logicielle, où plusieurs exemplaires d'un même programme font leurs calculs dans leur coin.
Points non abordés : dans ce qui va suivre, nous allons nous focaliser sur la redondance matérielle. La redondance des données, à savoir le domaine des codes correcteurs d'erreurs, est un sujet bien trop vaste pour être abordé dans ce cours. La redondance logicielle ne sera pas vue du tout, pour les mêmes raisons.
Prérequis : une bonne connaissance de l'architecture des ordinateurs est nécessaire pour comprendre ce qui va suivre. Vous devez, par exemple, savoir ce qu'est un processeur, une unité de calcul, une mémoire, un bit, connaître vos portes logiques et savoir créer des circuits électroniques relativement simples. La lecture des cinq premiers chapitres de « Fonctionnement d'un ordinateur depuis zéro », du même auteur, est vivement conseillée.
II. Redondance matérielle : généralités▲
De manière générale, les architectures tolérantes aux pannes dupliquent du matériel, que ce soit des ordinateurs, des composants (processeurs, mémoires, disques durs), voire des portions de composants (cœurs de processeurs, unités de calcul) : si un composant tombe en panne, les autres permettent au système de fonctionner. Par exemple, on peut utiliser plusieurs ordinateurs identiques, qui font la même chose en parallèle : si un ordinateur tombe en panne, les autres prendront le relais. Comme autre exemple, on peut utiliser plusieurs processeurs ou dupliquer les unités de calcul dans un processeur.
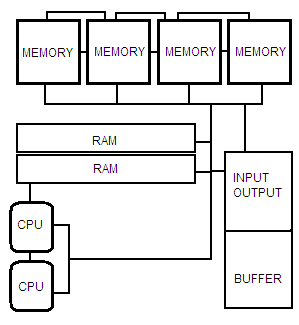
On peut classer les techniques de redondance matérielle en deux :
- les méthodes actives, où l'on doit détecter les erreurs et reconfigurer le circuit pour corriger la panne ;
- les méthodes passives, qui masquent les erreurs sans pour autant faire quoi que ce soit sur le composant fautif ;
- les méthodes hybrides, qui mélangent les méthodes passives et les méthodes actives.
III. Redondance matérielle passive▲
Avec la redondance matérielle passive, tous les composants travaillent en parallèle : ils reçoivent les données en entrée, les traitent et fournissent un résultat plus ou moins en même temps. La sortie des composants est reliée à un système qui se chargera de corriger les erreurs ou fautes en sortie, sans pour autant les détecter.
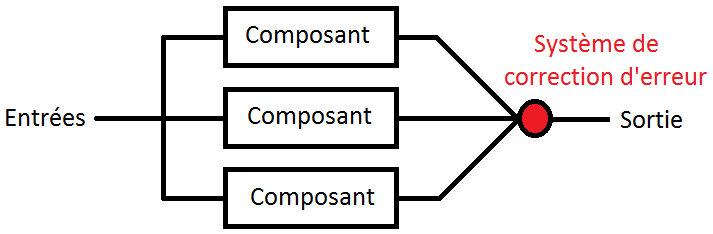
Par exemple, on peut imaginer ce que cela donnerait avec des unités de calcul redondantes : toutes les unités de calcul recevraient les opérandes en même temps, feraient leurs calculs indépendamment les unes des autres, et fourniraient leur résultat à un système qui corrigerait d'éventuelles erreurs de calcul ou pannes.
IV. Vote à majorité▲
Dans la plupart des cas, le système de correction des erreurs se base sur ce que l'on appelle un vote à majorité. Celui-ci peut se décliner en deux versions :
- un vote à majorité sur les résultats ;
- un vote à majorité bit à bit.
IV-A. Vote à majorité sur les résultats▲
Avec le vote à majorité sur les résultats, si différentes valeurs sont disponibles sur ses entrées, le système prend simplement la valeur majoritaire sur les autres. Par exemple, prenons le cas avec cinq composants : si un composant tombe en panne, les quatre autres donneront un résultat correct et à quatre sorties contre une, c'est le résultat correct qui l'emportera.

Il faut savoir que cette méthode ne fonctionne convenablement que si le nombre de composants est impair : dans le cas contraire, on peut avoir autant de composants en panne que de composants fonctionnels, ce qui fait qu'aucune majorité ne peut être dégagée.
Si le nombre de composants en panne est inférieur au nombre de composants sans panne, ce système de vote à majorité donnera systématiquement le bon résultat. Ainsi, utiliser trois composants permet de résister à une panne de composant, utiliser cinq composants permet de résister à une panne de deux composants, en utiliser sept permet de résister à trois composants en panne, etc. Avec kitxmlcodeinlinelatexdvpNfinkitxmlcodeinlinelatexdvp composants, on peut résister à kitxmlcodeinlinelatexdvpN \over 2finkitxmlcodeinlinelatexdvp pannes de composants.
IV-B. Vote à majorité bit à bit▲
Ce vote à majorité peut aussi s'effectuer non au niveau du résultat, mais au niveau des bits. Dans ce cas, le circuit de correction d'erreur va placer les bits des différents résultats sur la même colonne, et choisit pour chaque colonne le bit qui est majoritaire.

Ce calcul peut s'effectuer naturellement en utilisant ces portes à majorité, des portes logiques spécifiquement conçues pour déterminer quel est le bit majoritaire sur ses entrées : il suffit de lier les bits d'une même colonne aux entrées de cette porte pour obtenir le bit majoritaire en sortie. La porte logique à majorité la plus connue est celle à trois entrées, et celle-ci est illustrée plus bas. Son équation logique est la suivante, en posant que : kitxmlcodeinlinelatexdvpsfinkitxmlcodeinlinelatexdvp est sa sortie, et kitxmlcodeinlinelatexdvpafinkitxmlcodeinlinelatexdvp, kitxmlcodeinlinelatexdvpbfinkitxmlcodeinlinelatexdvp, kitxmlcodeinlinelatexdvpcfinkitxmlcodeinlinelatexdvp ses entrées : kitxmlcodeinlinelatexdvps = (a.b) + (a.c) + (b.c)finkitxmlcodeinlinelatexdvp.
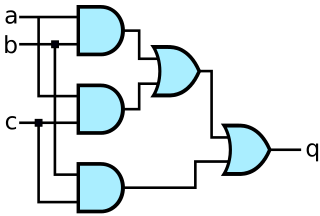
Des variantes de ce système de vote existent. Celles-ci consistent à prendre non pas le résultat ou bit majoritaire, mais seulement le plus fréquent (ou la médiane des différents résultats).
IV-C. Implémentation▲
Ce mécanisme fonctionne très bien, à un détail près : le circuit de vote à majorité est un point faillible du système, s'il tombe en panne, tout le système tombe en panne. Pour éviter cela, il est, là encore, possible de dupliquer ce système de vote à majorité, ce qui est utilisé quand le résultat doit être réutilisé par d'autres systèmes (qui sont eux-mêmes dupliqués).
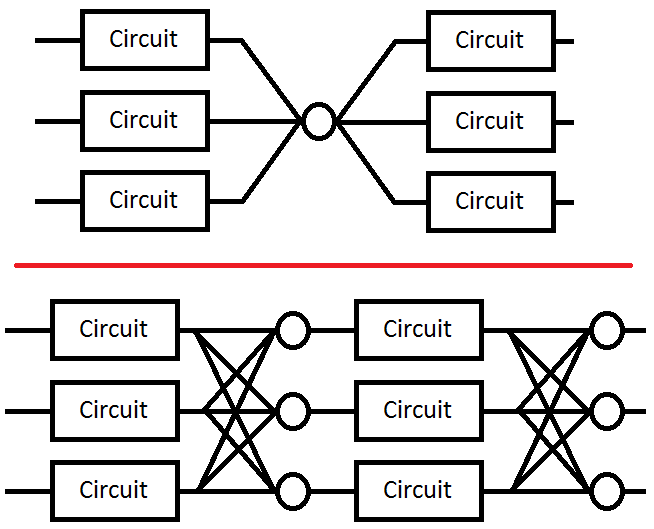
Ce système de vote à majorité peut s'utiliser pour les communications avec la mémoire. Il peut notamment servir pour gérer les lectures ou écritures dans une mémoire, voire les deux. On peut aussi l'utiliser pour gérer les communications à l'intérieur d'un composant. Par exemple, on pourrait imaginer utiliser ces méthodes pour l'unité de calcul et les registres : dans les schémas suivants, il suffirait de remplacer la mémoire par les bancs de registre (register files) et le processeur par l'unité de calcul. Bref, les possibilités sont relativement nombreuses.
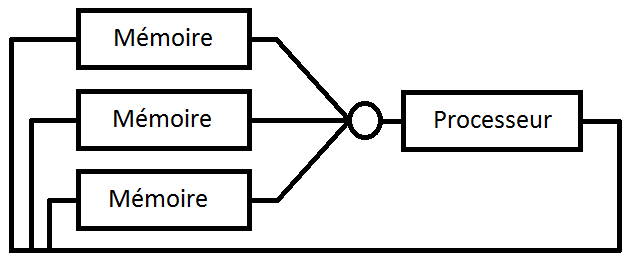
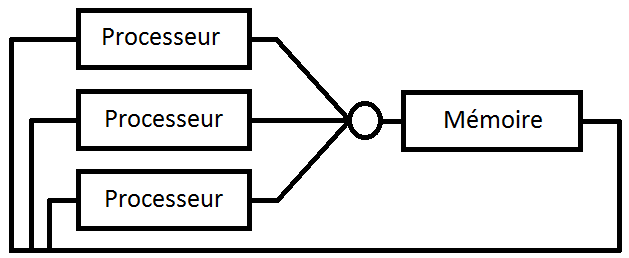
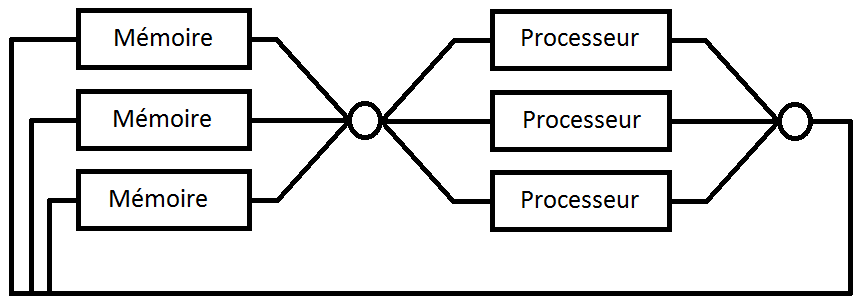
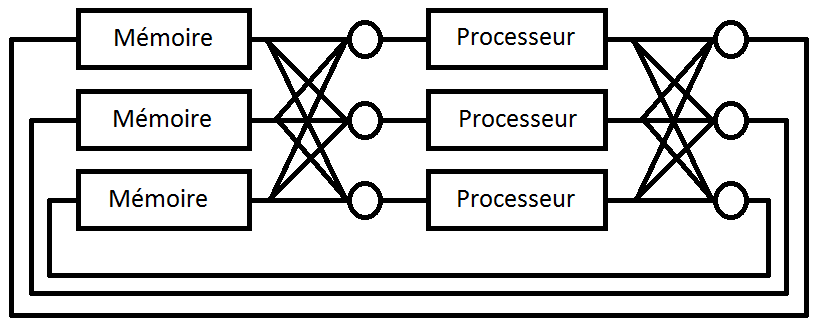
V. Redondance matérielle active▲
La redondance active ne masque pas les pannes comme peut le faire la redondance passive. Elle va détecter les pannes et passer le relais du composant en panne à un composant fonctionnel. Ces méthodes se déclinent en deux grandes catégories :
- d'un côté, celles où les composants travaillent en parallèle et où la reconfiguration du circuit suffit ;
- de l'autre, celles où un seul composant fonctionne à la fois et où la correction d'une panne demande de reprendre les calculs de zéro.
V-A. Duplication avec comparaison▲
Une première technique de redondance active se contente de dupliquer le composant en un composant principal et un composant de réserve. On peut alors détecter une erreur en comparant la sortie des deux composants : si elle est différente, on est certain qu'il y a eu une erreur (on suppose qu'il n'y en a pas eu en cas d'accord entre les deux composants). Une fois l'erreur détectée, on ne peut cependant pas la corriger.

Le premier processeur à utiliser cette méthode était l'EDVAC, dans les années 1950. Il comprenait deux unités de calcul, et continuait d'exécuter son programme tant que les deux unités de calcul donnaient des résultats identiques. En cas de non-agrément entre les deux unités de calcul, le processeur réexécutait l'instruction fautive.
On peut améliorer ce circuit afin qu'il puisse corriger l'erreur. Pour cela, on rajoute un troisième composant de réserve, dont on suppose qu'il ne sera pas en panne. Si une erreur est détectée par le comparateur, on préfère utiliser la sortie du composant de réserve.
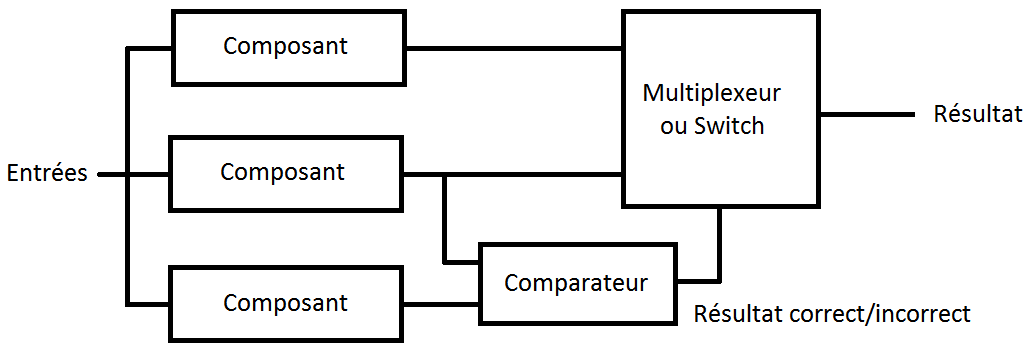
V-B. Standby Sparing▲
Avec cette méthode, le système de correction des pannes choisit un résultat parmi ceux qu'il reçoit et considère que ce résultat est le bon. En somme, il choisit la sortie d'un composant parmi toutes les autres : c'est donc un multiplexeur ou un switch. Quand le composant choisi tombe en panne, le multiplexeur/switch se reconfigure et choisit alors une autre sortie (celle d'un autre composant). Reste que cette configuration du switch demande de détecter les pannes, afin de commander le multiplexeur switch. On trouve donc, pour chaque composant, un système de détection des pannes, ainsi qu'un circuit combinatoire qui commande le multiplexeur/switch.
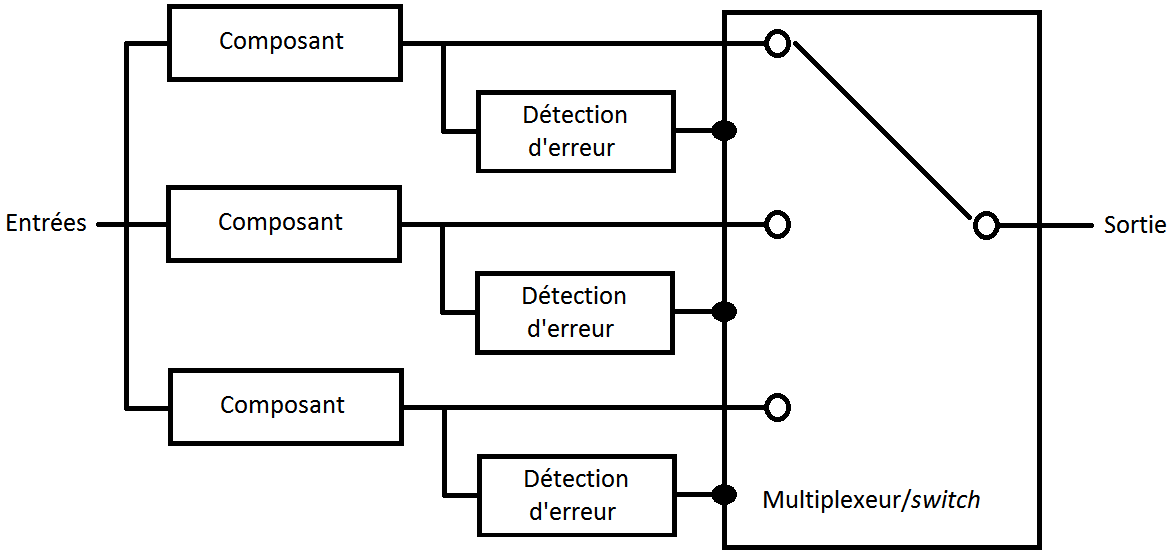
V-C. Pair And Spare▲
Il faut noter que les deux techniques précédentes sont loin d'être incompatibles. On peut notamment les utiliser de concert : la technique de duplication par comparaison peut être utilisée pour détecter les erreurs et la technique du Standby Sparing pour effectuer la correction. On peut aussi faire l'inverse.
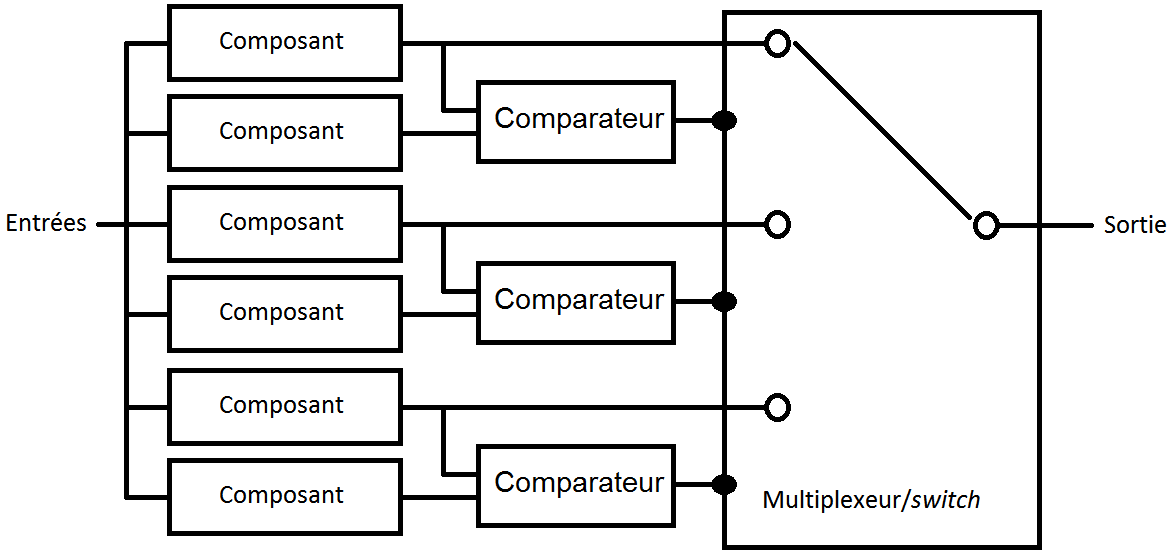

Un exemple typique est l'architecture Stratus (aussi connue « IBM/System 88 »). Celle-ci contient quatre processeurs logiques qui font leurs calculs en parallèle : le résultat est choisi parmi les processeurs sans panne. Une panne ou erreur est détectée avec duplication par comparaison : chaque processeur logique est dupliqué et une panne est détectée si les deux processeurs sont en désaccord sur le résultat. L'ensemble contient donc huit processeurs.
VI. Redondance matérielle hybride▲
Les méthodes de redondance hybride mélangent les techniques vues plus haut. Il en existe grosso modo trois principales :
- la redondance passive avec composants de réserve ;
- la redondance passive auto-correctrice ;
- la redondance à triple duplex.
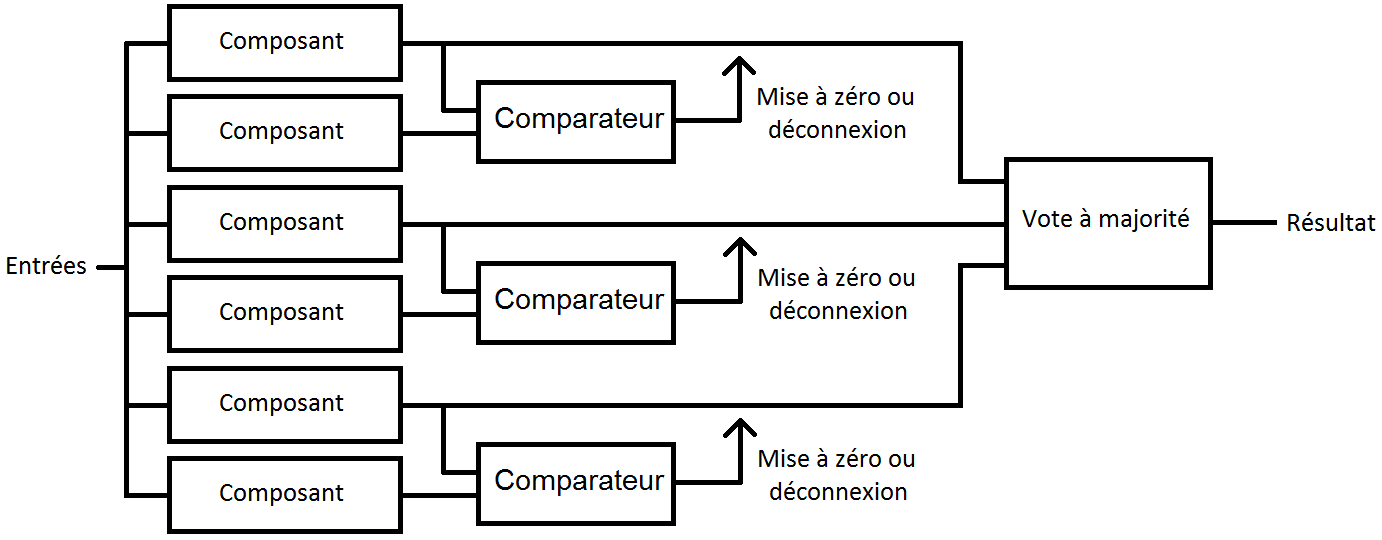
VI-A. Redondance à triple duplex▲
Avec la redondance à triple duplex, plusieurs composants qui utilisent la duplication avec comparaison sont suivis par une porte à majorité. Le principe de cette technique est simple : si un composant est en panne, alors son résultat ne doit pas être pris en compte dans le calcul du vote à majorité.
VI-B. Redondance passive auto-correctrice▲
La redondance passive auto-correctrice est similaire à la technique précédente, à un détail près : on n'utilise pas vraiment la duplication par comparaison de la même manière. Le principe de cette technique est le même que la précédente : si un composant est en panne, alors son résultat ne doit pas être pris en compte. Sauf que cette fois-ci, on détecte une panne en comparant le résultat du composant avec le vote majoritaire : il y a une panne si les deux ne sont pas identiques. Ainsi, au lieu d'avoir deux composants en entrée du comparateur, on n'en aura qu'un seul : l'autre entrée du comparateur sera reliée à la sortie de la porte à majorité.
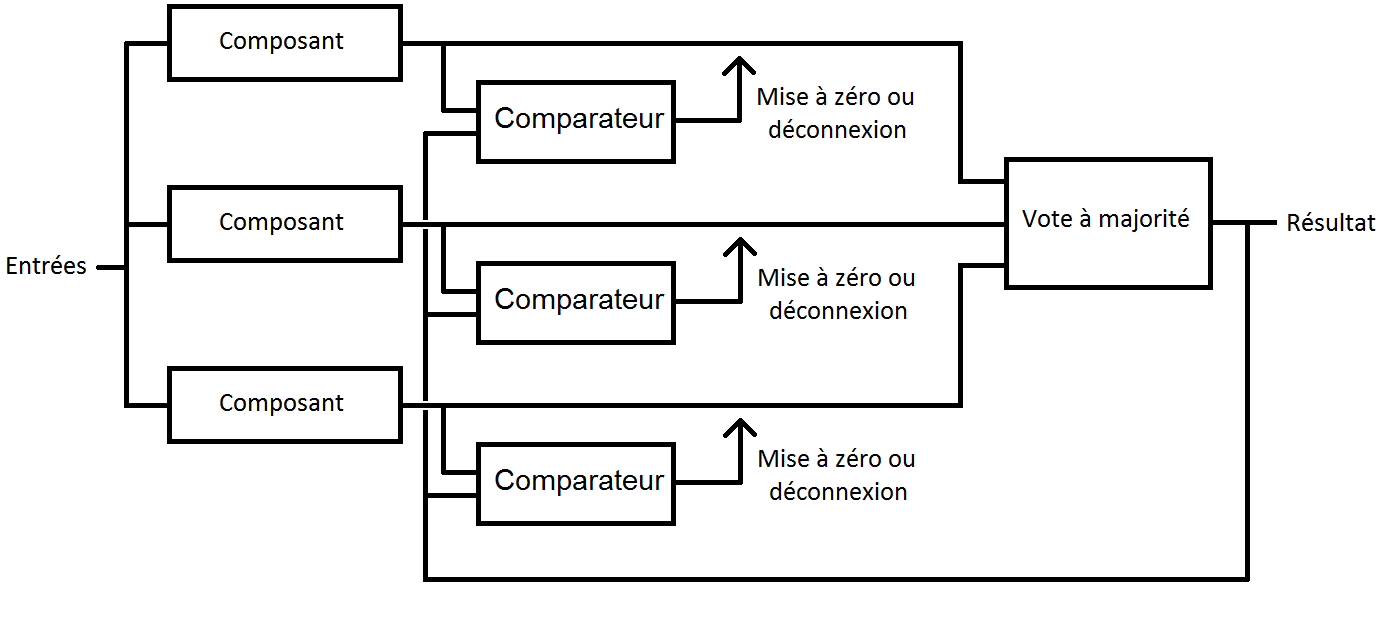
VI-C. Redondance passive avec composants de réserve▲
Avec la redondance passive avec composants de réserve, plusieurs modules qui utilisent la redondance active sont suivis par un système de vote à majorité.
Ces solutions matérielles pour tolérer les pannes sont relativement coûteuses, dupliquer du matériel n'étant pas sans coût. Aussi, les méthodes vues dans ce cours ne s'utilisent que pour des cas bien précis, où le besoin de fiabilité est fort, typiquement dans les grosses industries (aéronautique, spatiale, ferroviaire, automobile et autres). Il est peu probable qu'un développeur lambda ait affaire à ce genre d'architecture, alors que la redondance de données peut très bien faire partie de son quotidien.
